pi-accurate-vision
Accurate spatial reasoning over images — vision model extracts bounding boxes, LLM calculates exact distances
Package details
Install pi-accurate-vision from npm and Pi will load the resources declared by the package manifest.
$ pi install npm:pi-accurate-vision- Package
pi-accurate-vision- Version
0.1.4- Published
- May 27, 2026
- Downloads
- not available
- Author
- imkingjh999
- License
- MIT
- Types
- package
- Size
- 35.7 KB
- Dependencies
- 0 dependencies · 2 peers

Security note
Pi packages can execute code and influence agent behavior. Review the source before installing third-party packages.
README
pi-accurate-vision
Accurate spatial reasoning over images — vision model extracts bounding boxes, LLM calculates exact distances.
Vision models are great at describing what's in an image, but terrible at spatial reasoning. They get confused by visual elements like connecting lines, colors, and layout patterns. pi-accurate-vision solves this by separating perception from reasoning: a vision model extracts precise bounding-box coordinates, then an LLM performs mathematical spatial analysis.
Why Primitives Matter
The Problem
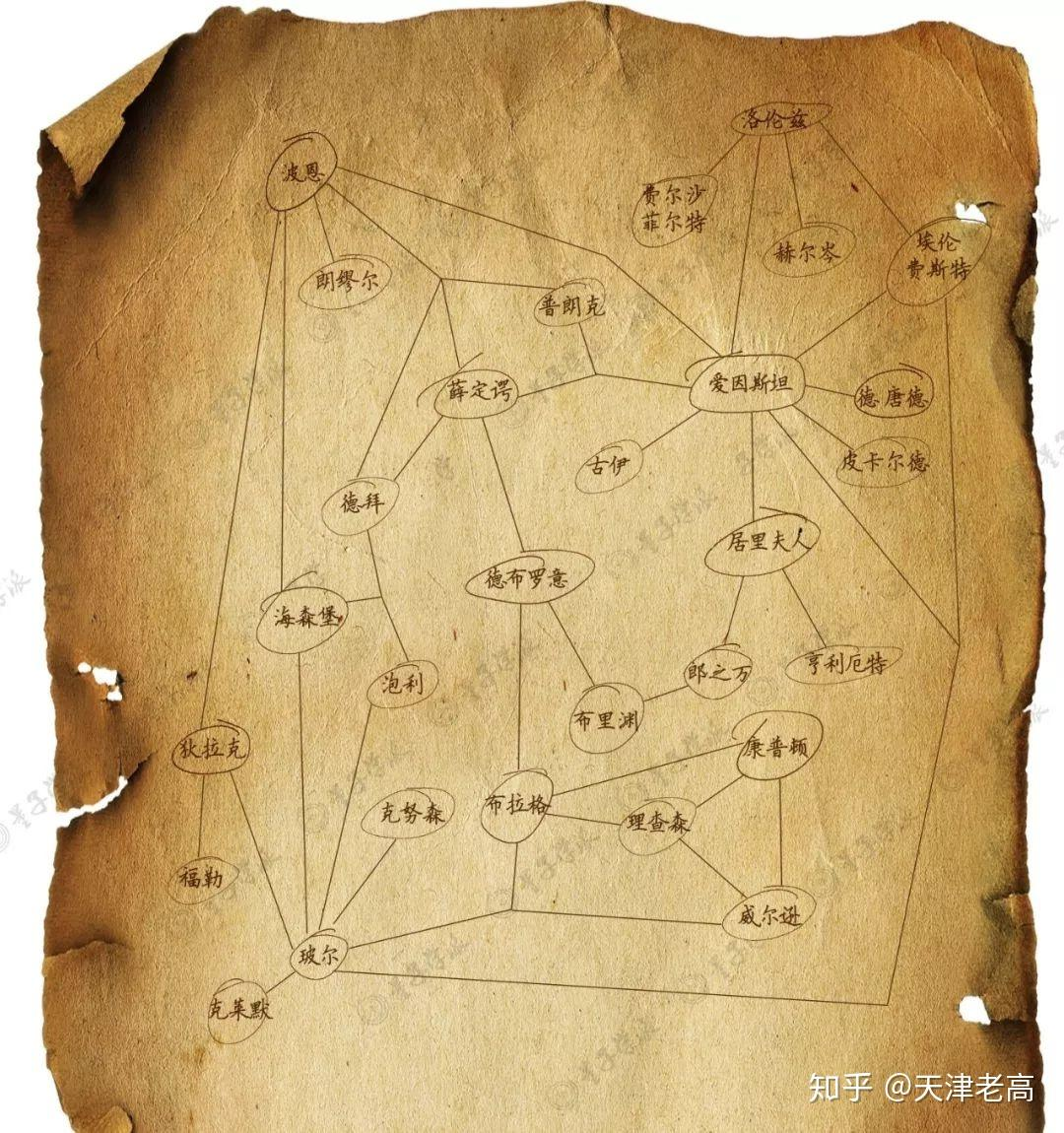
Given this scientist relationship network diagram:
Ask any vision model: "Ignoring the connecting lines, which text box is physically closest to 居里夫人 (Marie Curie)?"
They all get it wrong — answering 郎之万 (Langevin), likely influenced by the connecting lines or historical knowledge rather than actual spatial distance.
Without Primitives
The vision model gives only a text description — no coordinates:
An LLM receiving this can only guess based on historical knowledge:
"郎之万 is closest — they had a famous personal relationship..."
Result: ❌ Wrong — spatial reasoning replaced by knowledge-based guessing.
With Primitives
The vision model returns bounding-box coordinates for every detected object:
An LLM receiving this can calculate exact edge-to-edge distances:
居里夫人: [661, 450, 779, 508] ← target
皮卡尔德: [784, 375, 885, 428] ← dx=5, dy=22 → dist = 22.6 ✅ CLOSEST
亨利厄特: [739, 555, 849, 605] ← dx=0, dy=47 → dist = 47.0
古伊: [538, 385, 614, 435] ← dx=47, dy=15 → dist = 49.3
郎之万: [627, 565, 719, 618] ← dx=0, dy=57 → dist = 57.0 ← vision model's "answer"
Result: ✅ Correct — 皮卡尔德 (Piccard) is 22.6 units away, the true nearest.
Even GPT Gets It Wrong
GPT-4o looking directly at the same image also answers 郎之万 — influenced by the connecting lines, not actual spatial distance:
No matter how powerful the LLM, without precise coordinates, spatial reasoning over images is just guessing.
Benchmark Summary
| Approach | Answer | Correct? |
|---|---|---|
| Vision model (qwen3.5-omni-plus) alone | 郎之万 | ❌ |
| GPT-4o (direct image analysis) | 郎之万 | ❌ |
| Vision model + no primitives → LLM | 郎之万 | ❌ |
| Vision model + primitives → LLM | 皮卡尔德 | ✅ |
Install
npm install pi-accurate-vision
CLI Usage
# Analyze an image (reads config from ~/.deepseek/config.toml)
npx accurate-vision photo.png "What's in this image?"
# Output raw JSON
npx accurate-vision screenshot.png --json
# Disable bounding-box primitives
npx accurate-vision photo.png --no-primitives
# Override model/API
npx accurate-vision photo.png --model gpt-4o --api-key sk-xxx --base-url https://api.openai.com/v1
Library Usage
import { analyzeImage, resolveVisionConfig } from "pi-accurate-vision";
const config = resolveVisionConfig();
const result = await analyzeImage("./photo.png", config, "Describe the objects");
console.log(result.analysis);
Config
Reads from environment variables or a .env file in the current directory:
# .env
VISION_MODEL=qwen3.5-omni-plus-2026-03-15
VISION_API_KEY=your-api-key
VISION_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
VISION_PRIMITIVES=true
Priority: CLI flags > environment variables > .env file > defaults.
API
runVisionAnalysis(params)
Core function. Sends image to vision model, returns VisionAnalysis with:
note: structured description (overview, visible text, layout, charts, etc.)primitives: array of detected objects with bounding boxes (0–1000 normalised coordinates)
parseAnalysisResponse(raw)
Parse a vision model's JSON response. Handles multiple field name conventions.
formatVisionContext(analysis)
Format analysis as structured XML-like text for downstream LLM consumption.
resolveVisionConfig(overrides?)
Read and merge vision config from .env file + environment variables + explicit overrides.
Test
npx tsx --test src/vision/bridge.test.ts
License
MIT