pi-deep-research
Deep research skill for pi — structured search, reflection, and analysis.
Package details
Install pi-deep-research from npm and Pi will load the resources declared by the package manifest.
$ pi install npm:pi-deep-research- Package
pi-deep-research- Version
0.1.6- Published
- Apr 3, 2026
- Downloads
- 980/mo · 64/wk
- Author
- lavine
- License
- MIT
- Types
- extension, skill, prompt
- Size
- 55.1 KB
- Dependencies
- 0 dependencies · 0 peers
Pi manifest JSON
{
"skills": [
"./pi-deep-research"
],
"prompts": [
"./prompts"
],
"extensions": [
"./extension.ts"
]
}
Security note
Pi packages can execute code and influence agent behavior. Review the source before installing third-party packages.
README
pi-deep-research
Deep research skill for pi — structured search, reflection, and analysis.
![]()
Instead of shallow search-and-summarize, it enforces structured methodology: plan → search → reflect → iterate → report. A code-enforced checkpoint gate prevents the agent from rushing to conclusions before gathering enough evidence.
Install
pi install npm:pi-deep-research
Then set a search API key (at least one):
# Tavily (recommended, free: 1000 req/month)
export TAVILY_API_KEY="tvly-..."
# Brave Search (alternative, free: 2000 req/month)
export BRAVE_API_KEY="BSA..."
Usage
Slash Command
/research [depth] [topic]
Depth levels:
| Depth | Searches | Sources | Confidence | Time |
|---|---|---|---|---|
quick |
1-3 | 3-5 | 60% | ~2 min |
standard |
3-6 | 5-10 | 75% | ~5 min |
deep |
5-10 | 10-15 | 85% | ~10 min |
exhaustive |
10-20 | 15-30 | 95% | ~20 min |
Examples:
/research quick what is MCP protocol
/research deep competitive analysis of AI coding assistants
/research exhaustive quantum computing applications in drug discovery
Natural Language
The skill also activates when you ask the agent to research, investigate, or survey a topic:
Investigate the current state of AI agent frameworks
Investigate the current state of WebAssembly adoption
Quick Start
/research deep AI agent frameworks comparison 2026
Produces a comprehensive Markdown research report with executive summary, cross-referenced analysis, source credibility ratings, and contradiction tracking.
Demo
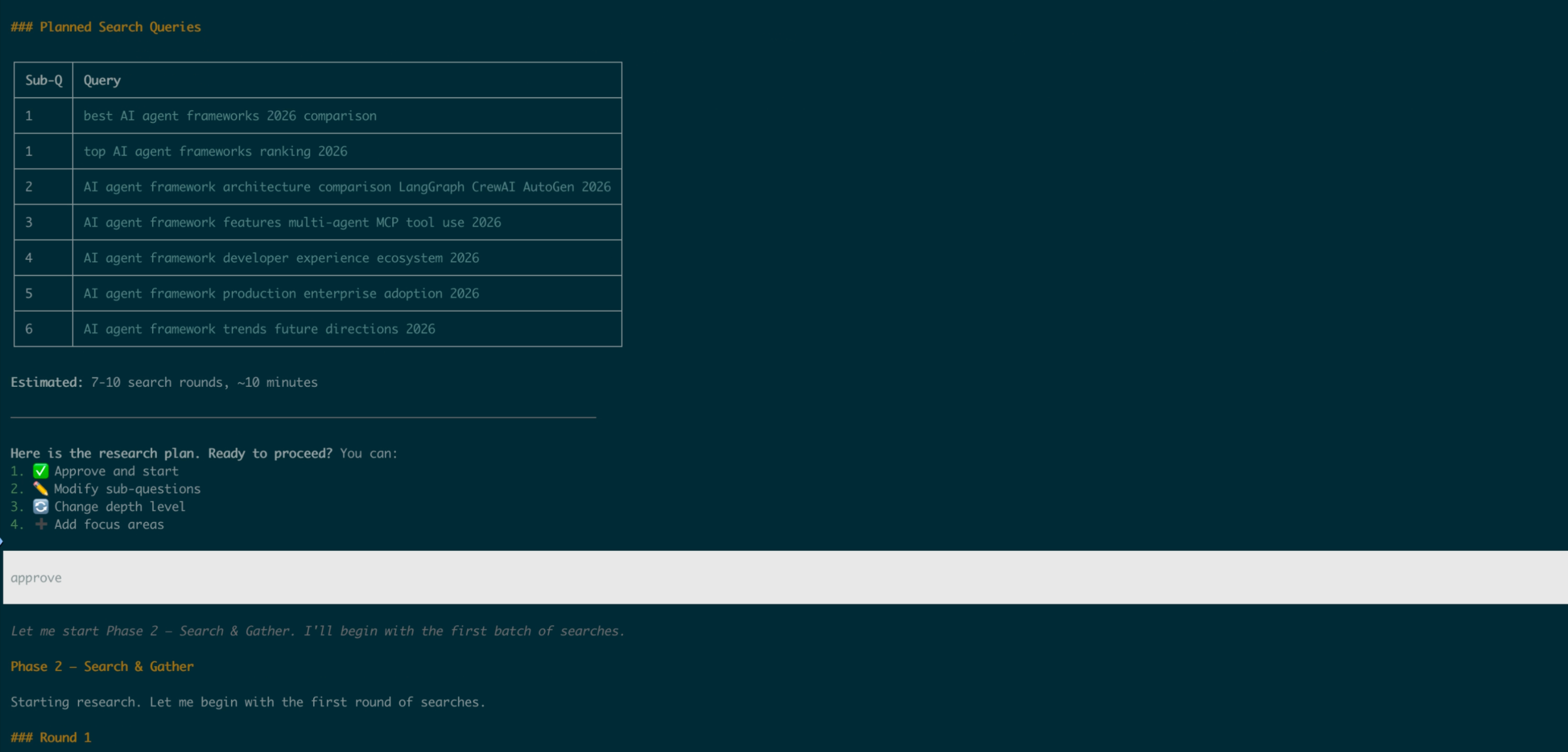
1. Start a research task
2. Review and approve the plan
The agent presents sub-questions and search queries, then waits for your approval before spending API calls.
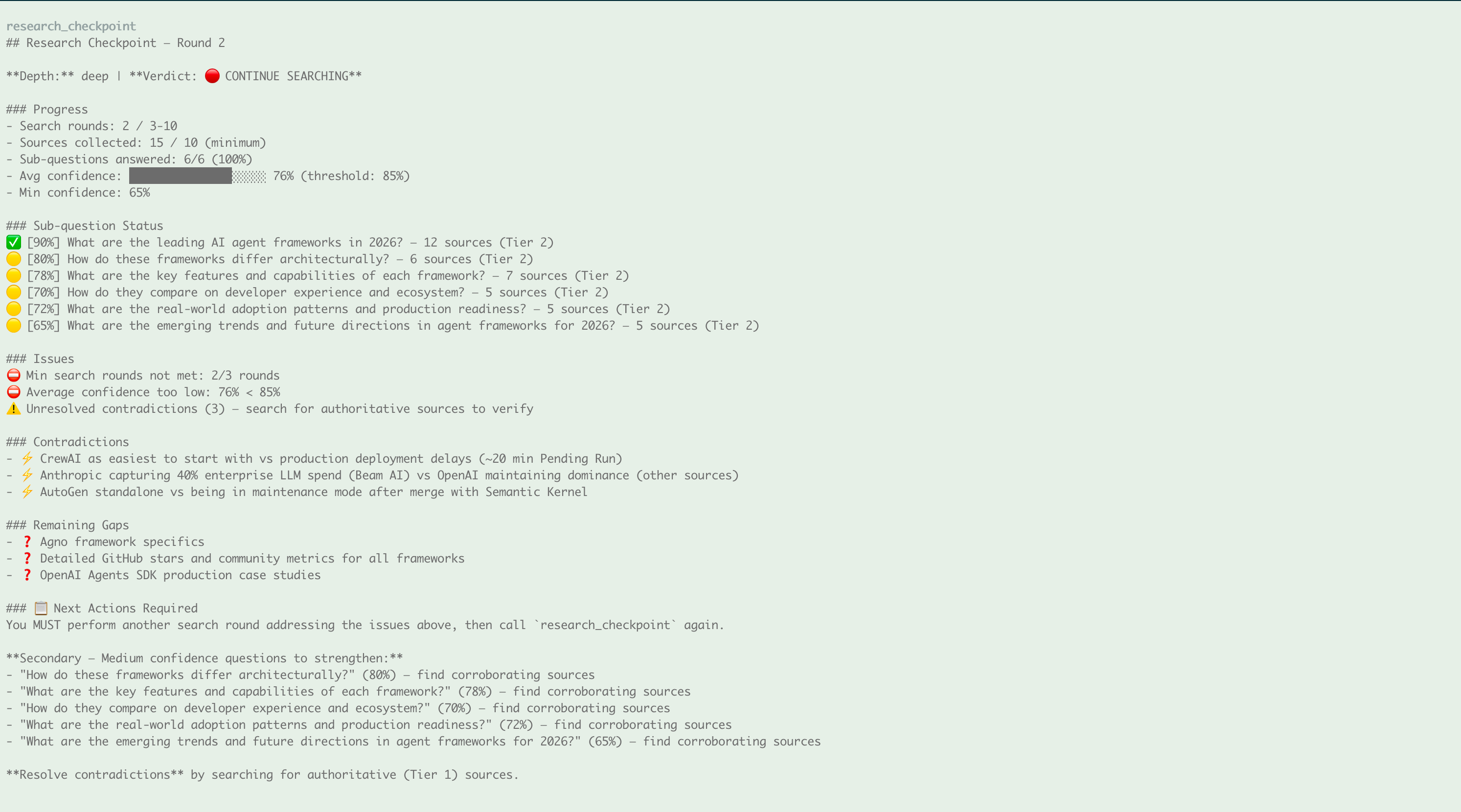
3. Checkpoint: keep searching or proceed?
After each search round, the research_checkpoint tool evaluates progress. Here it says 🔴 CONTINUE — confidence is too low and contradictions need resolving:
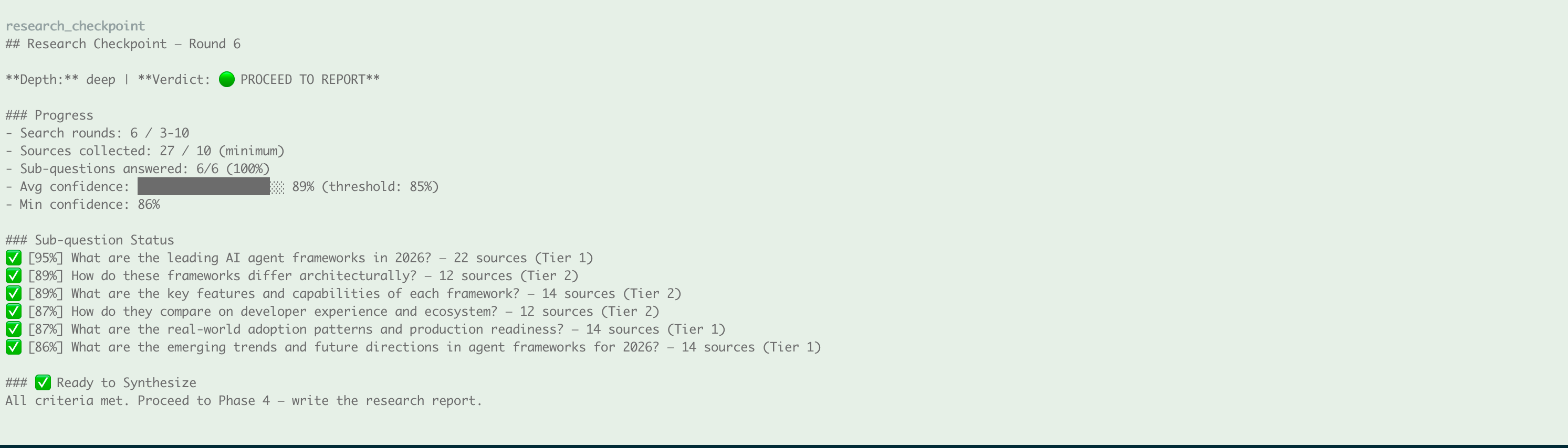
After more rounds, all criteria are met — 🟢 PROCEED:
4. Research complete
The agent generates a structured Markdown report with findings summary:
5. Full report output
A comprehensive research report with Executive Summary, Key Findings, cross-referenced analysis, and source citations:
💡 Tips: Visual HTML report
Pair with visual-explainer to turn the Markdown report into a styled HTML page:
pi install https://github.com/nicobailon/visual-explainer
Then ask: Turn this report into a visual HTML page
Why
LLMs doing "research" typically search once, skim snippets, and produce a surface-level summary. This skill fixes that by:
- Forcing deep reading — instructs the agent to use
web_extracton substantive sources, not just rely on search snippets - Code-enforced reflection — a
research_checkpointtool that evaluates progress against hard thresholds (min rounds, min sources, confidence score) and returns CONTINUE/PROCEED verdicts the agent must obey - Multi-hop reasoning — Entity Expansion, Temporal Progression, Conceptual Deepening, and Causal Chain patterns with concrete examples
- Analytical writing — anti-patterns ("Source A says X. Source B says Y." ❌) vs analytical style ("Evidence converges on X because..." ✅)
- Human-in-the-Loop — research plan must be approved before execution begins
How It Works
4-Phase Workflow
Phase 1: Understand & Plan
↓ (user approves plan)
Phase 2: Search & Gather (multi-hop reasoning, deep reading)
↓
Phase 3: Checkpoint & Reflect (MANDATORY — code-enforced)
↓ 🔴 CONTINUE? → back to Phase 2
↓ 🟢 PROCEED? → continue
Phase 4: Synthesize & Report (Markdown file)
Research Checkpoint (the key innovation)
After every search round, the agent must call the research_checkpoint tool. This tool runs 6 hard rules:
| Rule | What it checks |
|---|---|
| Min search rounds | Haven't done enough rounds for this depth level |
| Min sources | Not enough unique sources collected |
| Answered ratio | Too many sub-questions still unanswered |
| Avg confidence | Overall confidence below depth threshold |
| Low-confidence questions | Any sub-question below 40% confidence |
| Unresolved contradictions | Sources disagree and it hasn't been resolved |
If any rule fails → 🔴 CONTINUE (with specific guidance on what to search next). All rules pass → 🟢 PROCEED (agent may write the report).
Safety valve: after max rounds, forces PROCEED and flags remaining gaps.
Multi-Hop Reasoning Patterns
- Entity Expansion: Product → Company → Competitors → Market position
- Temporal Progression: Current state → Recent changes → Historical context
- Conceptual Deepening: Overview → Architecture → Trade-offs → Edge cases
- Causal Chain: Observation → Immediate cause → Root cause → Solutions
- Source Triangulation: Official docs × Independent analysis × Community experience
Report Output
Reports are saved as Markdown files: research_[topic]_[YYYYMMDD].md
Sections include:
- Executive Summary — conclusion first, then evidence
- Key Findings — ranked by importance with source citations
- Detailed Analysis — cross-referenced sub-questions with original analysis
- Comparison Table + Narrative — data and insight together
- Contradictions & Debates — vendor claims vs independent evidence
- Uncertainties & Gaps — explicitly flagged low-confidence areas
- Recommendations — primary, alternative, not recommended
- Sources Table — every URL with date and credibility tier (⭐🔵🟡🔴)
Package Contents
| File | Purpose |
|---|---|
SKILL.md |
Research workflow, behavioral mindset, multi-hop patterns, checkpoint rules |
extension.ts |
web_search + web_extract + research_checkpoint tools |
prompts/research.md |
/research slash command template |
references/config.md |
Depth thresholds, credibility tiers, confidence formula |
references/report-template.md |
Report structure, writing anti-patterns, quality requirements |
Configuration
Search Providers
| Provider | Env Variable | Free Tier |
|---|---|---|
| Tavily (recommended) | TAVILY_API_KEY |
1000 req/month |
| Brave Search | BRAVE_API_KEY |
2000 req/month |
The extension tries Tavily first, falls back to Brave. If neither is set, it shows a helpful error.
Depth Defaults
Override in references/config.md:
- Confidence thresholds per depth level
- Min/max search rounds
- Source count requirements
- Credibility tier weights
Design Decisions
This skill is built on insights from SuperClaude's DeepResearch architecture and academic foundations including:
- Reflexion (Shinn et al. 2023) — self-reflective loops with explicit evaluation
- Chain-of-Thought (Wei et al. 2022) — structured reasoning decomposition
- ReAct (Yao et al. 2023) — interleaved reasoning and action
- Multi-hop QA (Yang et al. 2018) — cross-document reasoning
Key design principles:
- Forceful imperative wording for reference file loading — LLMs skip polite requests
- Exact keyword matching for depth selection — prevents natural-language ambiguity from overriding explicit depth choices
- Human-in-the-Loop at plan stage — API calls are costly, confirm before executing
- Code-enforced checkpoints — LLMs self-evaluate optimistically, code doesn't
License
MIT